As a young hardware engineer, I started using programmable logic. What could be better, aside from maybe the price and power. You didn’t have to be too disciplined during the design phase because you could just reprogram the device if you had a bug or two. Heck your boss didn’t even have to know, just fix it in the lab. No PCB rework needed.
Even though this was years ago, and devices were no where near as complex as today’s FPGAs, this mindset still separates FPGA from ASIC design. With ASICs there can be a large non-recurring engineering cost and no forgiveness for design bugs, therefore up-front verification is not an option.
The “I can just fix it” FPGA attitude is a major reason a recent study showed that 68% of FPGAs are behind schedule and 83% of projects have a significant bug escape into production. On top of that, code that’s developed this way and at the time was deemed “good enough” has a habit of sticking around to become what’s knows as “legacy code” that no one wants to touch because it’s so poorly written that no one on the team today has any chance of understanding what it’s really doing.
When designing FPGAs, code quality is essential to staying on schedule, avoiding design iterations and worse, bugs found in production. This is especially true when it comes to high reliability applications such as automotive, space and medical devices where bugs can be extremely expensive or impossible to fix. But just what makes RTL (VHDL or SystemVerilog) quality code? The answer is, well, there isn’t just one thing that makes for quality code. It’s a combination of considerations from readability to architecture choices.
Over this series of blogs, we will investigate and do a deep dive into specific aspects of “quality code”. Part one will focus on readable and maintainable RTL code, highlighting some best practices. Part two will be a deep dive into Finite State Machine architectures and coding guidelines and part three will focus on the challenges around multiple Clock Domains.
Readable and maintainable code
During a code review, early in my career, my lead engineer had the audacity to take my code printout and throw it in a garbage can. Of course, as a young engineer I was flabbergasted because I had simulated the code and it worked like it was supposed to, or so I thought. He then said, in a reassuring voice, “now let me show you how to code so someone else can figure it out.”
What I learned next was that readable and maintainable code took some common discipline, starting with the basics such as naming conventions. It’s not so much whether the organization prefers big endian or little endian, spaces or tabs, prefixes or suffixes, underscores or hyphens or camel case, the important thing is to have a standard and stick to it. By standardizing on naming conventions for architectures, packages, signals, clocks, resets, etc. my code became clearer and as a side benefit, it reduced the code complexity. Going through code by hand to uphold those standards is incredibly tedious, but the task can be easily automated with a static analysis tool.
A simple and common mistake I made was to use hard coded numbers, especially in shared packages. While as the original coder I may understand exactly why I hard coded that specific number, 10 years down the line, when it’s time to update the device or functionality, the use of a hard coded number will add to confusion and delays.
Back to my code simulating, what I didn’t see lurking in my code were things that made it ripe for simulation vs synthesis mismatches. For example, variables that are used before they’re assigned might be unknown or might retain a previous value, which means possible mismatches between the simulation and actual functionality after synthesis. This simple mistake can mean the design works in simulation but then later fails in the lab or, worse, in the field.
Another common example of code quality issues is missing assignments in IF and Else blocks and case statements that will cause most synthesis tools to create latches in the design along with the registers. Implied latches can cause issues with timing, and different synthesis tools will do this in different ways, so change vendors, change implementations.
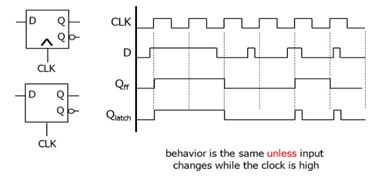
The goal of any tool is to succeed, and synthesis tools want to synthesize successfully, so they may give your code the benefit of the doubt, and assume your code is right until it’s proven wrong. Many tools will even accept common poor practices and “fix” them for you. Again, different tools, different “fixes.”
Another code quality issue is synchronous de-assertion of asynchronous resets. Some people pay little attention to how their reset will work in the real world. They just throw in a global reset just so the simulation looks “tidy” at Time Zero, but this isn’t enough. That reset must work in the real world. Keep in mind, a global reset is just that, global, so it has a large fanout and may have a significant delay and skew, so you need to buffer it properly. And because this reset is asynchronous, by definition it can happen at any time, and it forces the flip-flops to a known state immediately. That’s not a problem, but the de-assertion issue comes not when your reset pulse begins, but when it ends relative to the active clock edge. The minimum time between the inactive edge of your reset and the active edge of your clock is called recovery time. Violating recovery time is no different than violating setup or hold time. The easiest way to avoid this issue is to design your reset as shown here. The active edge can happen at any time, but the inactive edge is synchronous with the clock.
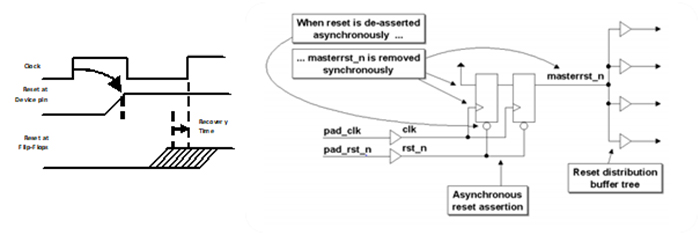
Finding and addressing code quality issues, such as naming conventions, reset issues, excessive area, low frequency and meantime between failures up front, as you code can significantly reduce the number of iterations through synthesis and place and route, improving productivity, reducing development costs and improving the reliability of a design.
When designing FPGAs, code quality is essential to staying on schedule, avoiding design iterations and worse, bugs found in production. The Visual Verification Suite from Blue Pearl Software provides RTL Analysis to identify coding style and structural issues up front. The RTL Analysis points out naming conventions as well as structural issues such as long paths and if-then-else analysis as you code, rather than late in the design cycle.
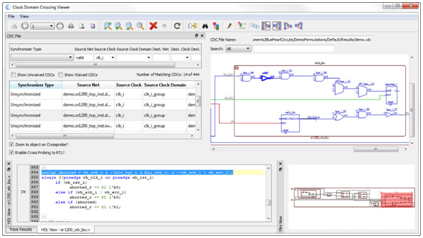
So, what is it that makes the Visual Verification Suite such a powerful debugging environment? It has a straightforward, understandable graphical user interface that runs on Windows or Linux, and quickly generates reports that show aspects of your design in general, like your highest fanout nets, or your longest if-then-else chains, and an easy-to-filter report window showing the specific issues it has found. The suite also includes numerous checks to catch violations of company specific naming conventions.
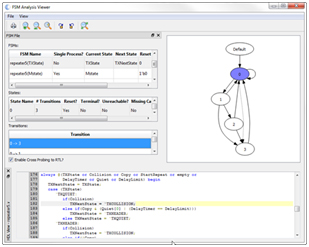
From these reports, or from the main window, you can open the schematic viewer directly to the area of interest, and with just a few mouse clicks you can turn that into a path schematic to isolate the issue even further. On top of that it provides views that help you with finite state machine analysis, CDCs, and long combinational paths. To learn more, we encourage you to sign up for a demonstration to learn more how the Visual Verification Suite can ensure quality code for high reliability FPGAs.
Check back for Part 2, A deep dive into Finite State Machine architectures and coding guidelines and Part 3, the challenges around multiple Clock Domains.